
In the past year, almost every enterprise conversation around AI has shifted.
The question is no longer “Should we use AI?”
The real question now is:
“How should we customise AI so it actually works for our business?”
That is where many technology leaders get stuck.
Because once you start exploring modern AI systems, you quickly encounter three major approaches:
All three influence how an AI system behaves.
But they do it in very different ways.
In simple terms:
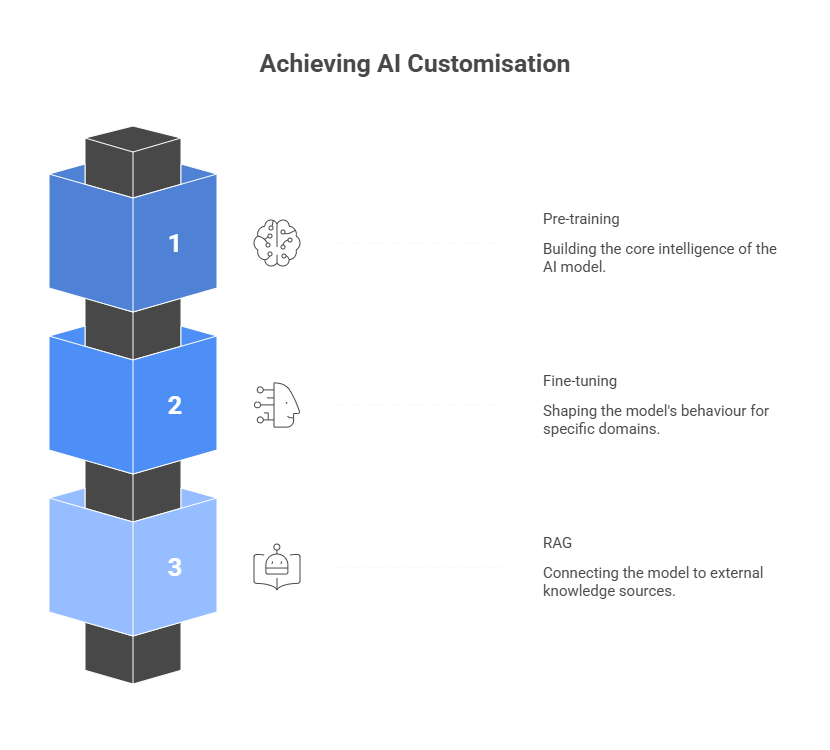
Pre-training
Fine-tuning
RAG (Retrieval-Augmented Generation)
And choosing the wrong path can have serious implications.
It can mean:
Over the past few years, we’ve helped organisations integrate AI into real operational workflows, from customer support automation to enterprise knowledge assistants.
And one thing becomes clear very quickly:
Success with AI is rarely about the model.
It is about choosing the right architecture.
So in this guide, I’ll break down Pre-Training vs Fine-Tuning vs RAG, and more importantly, when each approach actually makes sense.
But before we go deeper into each method, it helps to understand the three fundamental paths organisations take when customising AI.
Also read: How to Make an AI Model: Enterprise Development Guide
Most organisations today don’t build AI models from scratch.
They start with a foundation model; something like GPT, Claude, or Llama.
These models already understand language, reasoning patterns, and general knowledge.
But they still need to be adapted to your business.
That’s because a foundation model does not know:
That’s exactly where AI customisation comes in.
Now there are three main ways to do this.
And the key difference between them is where the change happens.
Each of these approaches modifies the AI system at a different level.
Pre-training builds the intelligence of the model itself.
Fine-tuning teaches the model how to behave in a specific domain.
RAG leaves the model unchanged but connects it to external knowledge.
Think of it like this.
Pre-training builds the brain.
Fine-tuning trains the brain.
RAG gives the brain access to a library.
In practice, most enterprise AI systems combine more than one of these layers.
But to understand how that works, we first need to look at the foundation layer, that is pre-training.
Also read: Types of AI Models: Guide for Enterprise Leaders
When people talk about training AI models, they are usually referring to pre-training.
This is the stage where a model learns the fundamentals of language.
During pre-training, a model is trained on extremely large datasets such as:
The goal is simple; to teach the model how language works, how ideas connect, how reasoning flows from one concept to another.
This process produces what we now call foundation models.
Models like GPT, Claude, and Llama all began with massive pre-training runs.
But here is the important part.
Pre-training is extraordinarily expensive.
Training a modern large language model can require:
That is why only a small group of organisations actually do it.
Companies like:
For most enterprises, pre-training is not the goal. Enterprises are not trying to invent the next GPT.
They are trying to solve real operational problems such as:
For those kinds of problems, starting with an existing foundation model is far more practical.
Which leads us to the next layer of AI customisation.
Instead of building the brain from scratch, many organisations simply teach the model how to think in their domain.
That approach is called fine-tuning.
If pre-training builds the brain of an AI model, fine-tuning teaches it how to think in a specific environment.
Most modern AI systems start with a pre-trained foundation model.
These models already understand language extremely well.
But they are still generic and they don’t understand the nuances of your industry.
They don’t know how your teams communicate.
They don’t understand the terminology your business uses every day.
That is where fine-tuning comes in.
Fine-tuning adapts a pre-trained model using smaller, domain-specific datasets.
These datasets might include:
The goal of fine tuning is not to teach the model language again.
It is to teach the model how language works in your domain.
For example:
A financial AI assistant might be fine-tuned on:
A legal assistant might be fine-tuned on:
The result is a model that behaves differently, uses the right terminology, and understands domain-specific patterns.
And it produces far more consistent outputs.
But fine-tuning also has a limitation.
The model only knows the information it was trained on.
If the underlying knowledge changes, the model needs to be trained again.
Which brings us to a different approach.
Instead of constantly retraining the model, what if we simply gave it access to the latest knowledge whenever it needs it?
That idea leads us to RAG.
RAG, or Retrieval-Augmented Generation, solves a different problem than fine-tuning.
Instead of modifying the model itself, RAG changes how the model accesses knowledge.
In a RAG architecture, the AI model is connected to external information sources.
These sources might include:
When a user asks a question, the system performs three steps.
The model then generates an answer based on that information.
In other words, the model becomes a language interface to your data.
This approach has a powerful advantage.
It means that knowledge does not live inside the model anymore.
The knowledge lives in your systems.
That means updates are easy.
If you update the documents, the AI system immediately reflects the change; no retraining is required.
This is why RAG architecture has become the most common approach for enterprise AI systems.
Typical RAG use cases include:
In many organisations, RAG becomes the fastest path from AI experimentation to production.
But that raises an important question.
If we now have three approaches (Pre-Training, Fine-Tuning, and RAG) how should an organisation decide which one to use?
When leaders compare Pre-Training vs Fine-Tuning vs RAG, the question they are asking is simple:
Where should the knowledge live?
Inside the model?
Or outside the model?
Each approach answers that question differently.
From an enterprise perspective, the decision usually comes down to three scenarios.

In practice, most enterprises begin with RAG as it is the fastest way to connect AI with internal knowledge.
Let’s walk through a few examples, because in most organisations, the choice of AI architecture depends on the problem being solved.
Imagine an organisation with thousands of internal documents such as SOPs, HR policies, training manuals, and product documentation.
Employees constantly ask the same questions.
Where is this policy?
How does this process work?
What does the latest version of this guideline say?
In this case, RAG is usually the best approach.
The AI system retrieves relevant documents from the knowledge base and generates answers grounded in those documents.
The advantage is simple.
If the policy changes tomorrow, updating the document automatically updates the AI responses.
No retraining will be required.
Now consider a customer support system that needs to respond consistently to user queries.
The system must understand:
Here, fine-tuning can significantly improve performance.
By training the model on historical support conversations and product documentation, the AI learns how support teams communicate and how issues are resolved.
Finally, imagine a technology company building an entirely new AI product; perhaps a specialised language model for scientific research.
In this scenario, pre-training might be necessary.
The organisation may need to train a model on massive proprietary datasets to create unique capabilities.
But this is relatively rare.
For most enterprises, the practical architecture usually starts with RAG, adds fine-tuning where needed, and builds on existing pre-trained foundation models.
And that is precisely why modern AI systems increasingly combine these approaches.
That combination is what we call the hybrid AI stack.
Modern enterprise AI systems rarely rely on just one approach.
Instead, they combine Pre-Training, Fine-Tuning, and RAG into a layered architecture.
You can think of it as three levels working together.
Foundation Model (Pre-trained)
↓
Domain Behaviour (Fine-tuning)
↓
Enterprise Knowledge (RAG)

Each layer solves a different problem.
Pre-training provides general intelligence.
Fine-tuning introduces domain expertise.
RAG connects the model to real-time knowledge.
Together, they create a system that is both intelligent and practical.
This will be clearer with an example.
Consider a legal AI assistant.
The underlying model may already understand language because of pre-training.
It might then be fine-tuned on legal terminology so it understands contracts and case law.
Finally, a RAG system connects it to a database of legal documents so it can reference the latest cases.
The result is an AI system that can:
This layered approach is increasingly becoming the standard enterprise AI architecture.
But building that architecture requires more than just models.
It requires engineering; it requires integration.
And it requires a clear understanding of how AI fits into real business workflows.
That is where the right implementation partner becomes critical.
At Neuronimbus, we approach AI a little differently.
We don’t start with the model.
We start with the business problem.
Irrespective of whom we work with, the first few questions are always the same:
Where is friction in the workflow?
Where are teams spending time on repetitive tasks?
Where is knowledge difficult to access?
Once those questions are clear, the architecture becomes much easier to design.
In many cases, the solution involves combining:
The goal is always the same: use AI to simplify work, not complicate it.
Neuronimbus solutions are designed to integrate with the platforms organisations already rely on — including CRM systems, ticketing tools, knowledge bases, and internal data platforms.
Because AI only becomes valuable when it fits naturally into how teams already operate.
And when implemented correctly, the combination of Pre-Training, Fine-Tuning, and RAG can transform how organisations access knowledge, automate processes, and scale expertise across the enterprise.
Pre-training builds the core intelligence of an AI model, fine-tuning adjusts its behaviour for specific tasks or industries, and RAG improves responses by connecting the model to external, real-time knowledge sources.
Fine-tuning is ideal when a business needs the AI model to follow domain-specific language, tone, or output patterns consistently. RAG is better when the model needs access to frequently changing information.
RAG allows AI systems to retrieve and use the latest information from internal documents, knowledge bases, or databases without retraining the model, making it faster and more scalable for enterprise use.
No, most businesses do not need pre-training because it is expensive and resource-intensive. Most enterprises can build effective AI systems using existing foundation models combined with fine-tuning and RAG.
Yes, many modern enterprise AI systems use all three in a hybrid architecture. Pre-training provides the foundation, fine-tuning adds domain expertise, and RAG connects the system to real-time business knowledge.




Let Neuronimbus chart your course to a higher growth trajectory. Drop us a line, we'll get the conversation started.





Call Us

Schedule a Call
Your Next Big Idea or Transforming Your Brand Digitally
Let's talk about how we can make it happen.


