
Over the last few years, artificial intelligence has moved from research labs into everyday business operations.
Companies are using AI to improve customer support, automate internal processes, detect fraud, and make faster decisions from large volumes of data.
But something interesting is now happening.
More organizations are asking a deeper question:
Should we train our own AI model instead of relying entirely on off-the-shelf AI tools?
The reason is simple.
Generic AI systems are powerful, but they are trained on general internet data. Businesses, however, run on highly specific information:
When companies begin to combine AI with these unique data assets, the idea of building a custom AI model becomes very attractive.
However, learning how to train an AI model is not just a technical project.
It involves several moving parts:
In this guide, we will walk through how enterprises approach AI model training, when it actually makes sense to do it, and the steps required to make it work in production environments.
To start with, we need to answer a fundamental strategic question.
Also read: AI in Financial Services: Key Insights
Honest answer: for most organizations, most of the time, you don't need to train from scratch. The real question is — what level of customization does your use case actually need?
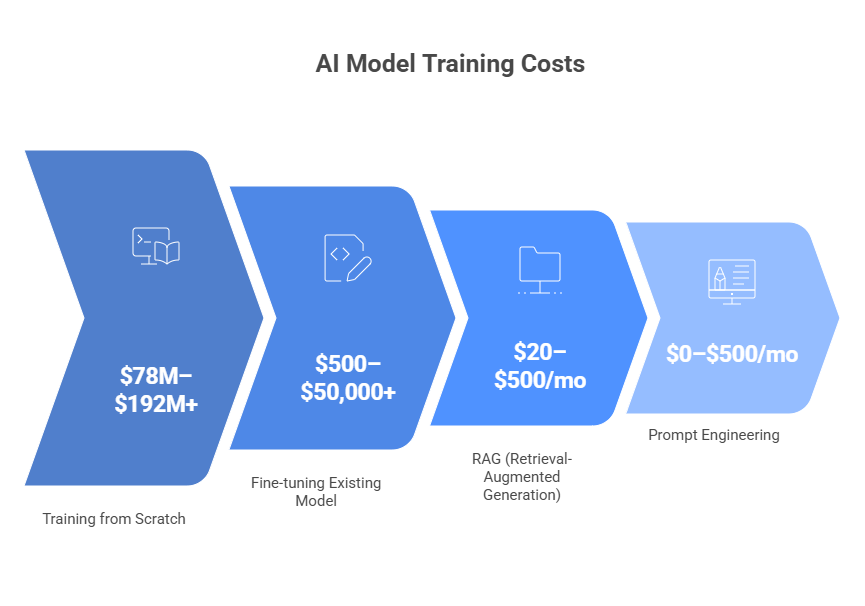
The insight most teams miss:
So, the goal is not to build the most sophisticated model. It is to build the right one.
There are genuine situations where deeper customization is the right call. You should seriously consider training a custom model when:
You probably don't need a custom model if your task is general-purpose, your API spend is under ~$15K/month, or your knowledge base changes frequently (a document update costs $0 in RAG and $500–$5,000 in a fine-tuned model).
DBS Bank built over 1,500 in-house AI models generating SGD 750 million in economic value in 2024.
Why? Because their trading, KYC, and fraud data legally cannot leave a regulated environment. That's not a preference; it's a constraint.
Once the decision to build is made, the next question is: what do you actually need in place before training starts?
Also read: AI Development Services: Choosing the Best Partner
Most AI projects don't fail because the technology is hard. They fail because the team underestimated what they needed before they started.
Here is your readiness checklist.
Not just data — AI-ready data. Data preparation consumes 60–80% of total project time. You need relevant, clean, labeled, and governed data before a single training run begins.
For healthcare, PHI must be de-identified. For financial services, audit trails are mandatory.
H100 GPUs now rent for $1.50–$3.00/hour in cloud, down over 60% since early 2024. Start in cloud for experimentation. Consider on-premises (an 8-GPU DGX costs ~$250–300K) only when your workloads are sustained and predictable. 68% of US enterprises use a hybrid approach.
PyTorch dominates research (75% of NeurIPS 2024 papers). Hugging Face Transformers is the standard for LLM fine-tuning. For the base model, start open-source: Llama 3/4 (most adopted), Mistral (most permissive license), Phi-3/4 (best small model performance).
A minimum viable fine-tuning project needs 5–8 people: ML engineers ($160K–$300K+), data scientists, MLOps engineers, data engineers, and annotators. The global AI talent demand-to-supply ratio is 3.2:1. These roles take 12–18 months to hire through standard recruiting.
MLflow, Weights & Biases, or cloud-native options (SageMaker, Vertex AI). This is not optional. 60% of total AI project costs land after deployment — in monitoring, drift detection, and retraining. Plan for it upfront.
Most guides show you how to run training code. This covers how to run an AI model training project — the lifecycle that determines whether you ship something that works or spend six months building a prototype.
Translate your business objective into a measurable ML KPI before any data collection begins. Walmart's demand forecasting model started with one metric: reduce stockout rate by 20%. Everything downstream was anchored to that number. Also confirm compliance requirements here before you touch any data.
This is the stage most teams underestimate. Plan two months of a three-month project for data. You need documented lineage, access controls, compliance sign-off, and a bias audit before training begins.
For supervised learning tasks, every training example needs a correct label. Active learning can reduce labeling effort by 30–40%. Budget for expert annotation in specialized domains — medical labeling runs 3–5× standard rates.
Start with a pre-trained open-source model. Then choose your fine-tuning method:
Why LoRA matters for enterprise budgets
LoRA (Low-Rank Adaptation) trains only 1–2% of a model's parameters. A Llama 3 70B fine-tuned with LoRA costs 80–90% less than full fine-tuning, with 90–95% of the performance on domain-specific tasks.
For most enterprise applications, LoRA is the right answer, with smaller adapter files, faster iteration, dramatically lower cost.
Test on held-out data your model has never seen. For LLMs, red-team deliberately try to produce harmful, biased, or wrong outputs before your users do. Document everything in a Model Card. The FDA and EU AI Act both require documented lifecycle evaluation for high-risk AI.
Shadow deployment → canary release (5–10% traffic) → full production. Containerize with Docker, orchestrate with Kubernetes. Never push directly to 100% traffic without a rollback plan.
A fraud model trained on 2023 patterns will miss 2025 fraud vectors if nobody is watching. Budget 15–40% of initial development cost annually for ongoing operations.
The process, executed well, produces working AI. Where it breaks down and why it breaks down so often is what we cover next.
Over 80% of AI projects fail, which is twice the rate of non-AI IT projects (RAND Corp, 2024).
42% of companies abandoned most of their AI initiatives in 2025, up from 17% the year before (S&P Global). These aren't technology failures. They are planning failures.
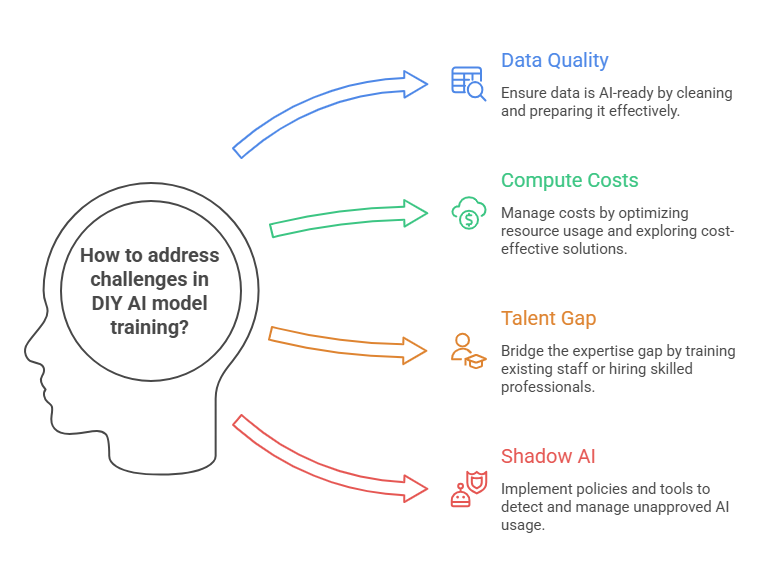
The common causes:
Only 6% of organizations qualify as AI high performers and are generating over 5% EBIT impact from AI (McKinsey 2025). What separates them isn't bigger budgets. It's how they approach the work.
Apply these practices and you will be in a very different position than most teams. Whether you build independently or with a partner is the final decision.
For many enterprises, the challenge is not simply learning how to train an AI model.
The real challenge is building an AI system that works reliably inside complex business environments.
This requires a combination of capabilities.
Not just machine learning.
But also:
This is the area where companies like Neuronimbus focus their efforts.
Neuronimbus helps organizations train custom AI models that are grounded in real operational needs rather than experimental use cases.
Its approach combines:
The goal is simple.
To help businesses move from AI experimentation to real production systems — where AI models deliver measurable operational value.
And that is ultimately what makes training your own AI model worthwhile.
A business should consider training its own AI model when it has unique proprietary data, strict compliance requirements, hard latency needs, highly specialized domain use cases, or when AI itself is the core product and competitive advantage.
No. Most companies do not need to train a model from scratch. In most cases, prompt engineering, RAG, or fine-tuning an existing model is enough and delivers better ROI with lower cost, faster deployment, and less complexity.
Before training begins, companies need AI-ready data, compute infrastructure, a suitable base model and framework, a skilled cross-functional team, and MLOps tools for monitoring, deployment, and retraining.
The biggest challenge is usually not the model itself but poor planning. Common problems include low-quality data, unexpected compute costs, lack of skilled talent, weak governance, and no strategy for monitoring or retraining after deployment.
Best practices include starting small, building strong data governance early, integrating responsible AI checks, planning MLOps from day one, redesigning workflows around AI, and assigning a dedicated AI owner to manage lifecycle performance.




Let Neuronimbus chart your course to a higher growth trajectory. Drop us a line, we'll get the conversation started.





Call Us

Schedule a Call
Your Next Big Idea or Transforming Your Brand Digitally
Let's talk about how we can make it happen.


