You’re trying to figure out which large language model is best for your business, and we get it. The landscape changes by the day. What was state-of-the-art yesterday is already old news. That’s why we at Neuronimbus spend so much time digging into the technology, because the right choice can give you a real competitive edge.
We’ll begin our discussion with Llama, as its open-source nature sets the standard for businesses seeking greater control and security.
Most of the practical innovation in enterprise AI now centers around open-source models.
Why?
Because they offer:
If you were in this space a year or so ago, you were probably looking at LLaMA 2.
LLaMA 2, launched in 2023, offered sizes from 7B to 70B parameters and a solid 4K token context window. It was text-only, performed well in English tasks, and was easy to fine‑tune—still, it had limitations in scale and modality.
Fast forward to 2025: LLaMA 4 is a completely new beast. Here’s how the LLaMA 2 versus LLaMA 4 comparison looks like, in terms of LLaMA 4’s updates:
.webp)
To put it simply: LLaMA 4 is to LLaMA 2 what a jet is to a bicycle. If LLaMA 2 was your “starter” open AI, LLaMA 4 is the production-class model built for scale, capability, and global deployment.
But open models aren’t the only game in town.
The world of LLMs isn’t a one-horse race.
While Llama 4 is powerful, it has serious competitors, each with its own strengths.
LLaMA 4, Meta’s latest flagship, sets a new bar for open-source language models in 2025. It’s not just about text anymore—LLaMA 4 handles both text and images, supports over a dozen languages, and features a massive context window (up to 10 million tokens in its largest variants). It’s engineered for cost-efficiency and “agentic” workflows, making it a powerhouse for enterprise automation, knowledge management, and global-scale apps.
.webp)
So, if your business demands enterprise-grade scale, automation, and deep AI integration, LLaMA 4 leads. For global, resource-efficient, and diverse deployments, Gemma 3 is a compelling alternative.
As of August 2025, the AI race is defined by three cutting-edge models: Llama 4 (Meta), GPT-5 (OpenAI), and Claude 4 (Anthropic). Each brings something new to the table in multimodality, reasoning, coding, and agent capabilities.
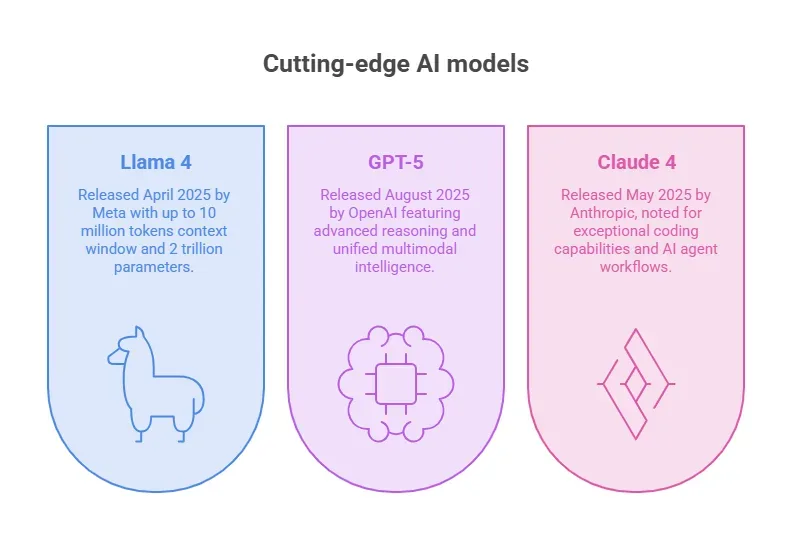
All three models—Llama 4, GPT-5, and Claude 4—push the boundaries far beyond what was possible just a year ago.
Now you have a solid understanding of the current market, but we all know that in AI, today’s top model can quickly become tomorrow’s runner-up. The pace of development is just incredible. We’re already seeing hints of what’s next. Meta has teased even larger, more capable versions of Llama 3 and is already on the horizon with its next-generation models like Llama 4. Meanwhile, Google is advancing its own ecosystem with models like Gemma 3 and new versions of Gemini.
Now that we’ve broken down the technical specs, let’s talk about what really matters. At the end of the day, an LLM is a tool, not a solution. The right tool depends entirely on the job you need it to do.
You should be asking questions like:
For instance, a legal firm that needs to summarize confidential contracts will prioritize data security and customization over raw speed. A marketing agency creating mass content might prioritize cost-per-token.
This is exactly where we come in.
At Neuronimbus, we understand that this is more than a technology choice. It’s a strategic one.
As your digital transformation partner, we partner with you to understand your specific business challenges and design a complete, end-to-end solution.
So, what’s the final word? The truth is, there is no single answer.
Navigating this complexity is what we do best. The choice of an LLM is a long-term strategic decision, and getting it right can save you a tremendous amount of time, money, and effort. Neuronimbus is here to help you turn these complex technological choices into clear, strategic advantages. We’ll help you find the perfect fit and build a solution that truly works.
A large language model (LLM) is an AI trained on huge amounts of text data to understand and generate human-like language. It uses neural networks, especially transformers, to predict the next word in a sequence and handle complex language tasks.
Performance comparison usually focuses on accuracy (benchmark tests), speed, cost, and context window size. Tools like the LLM Leaderboard or AI model comparison charts show which models perform best for tasks like code generation, summarization, or multilingual support.
Models like GPT-4, Gemini, and Claude 3.5 are designed for fast, real-time data processing. These models excel in live chat, virtual assistants, or rapid document analysis, supporting dynamic enterprise applications that require quick, reliable responses.
The leading open-source LLMs in 2025 include Meta’s LLaMA 3.1, Google’s Gemma 3, Falcon, and Mistral. These are popular for flexibility, cost-effectiveness, and the ability to customize and deploy on-premises or on your preferred cloud infrastructure.
You can check out HuggingFace’s Open LLM Leaderboard for regularly updated model comparison tables. These sites rank LLMs by intelligence, price, speed, and use case suitability, making decision-making easier.
.webp)



Let Neuronimbus chart your course to a higher growth trajectory. Drop us a line, we'll get the conversation started.





Call Us

Schedule a Call
Your Next Big Idea or Transforming Your Brand Digitally
Let's talk about how we can make it happen.



